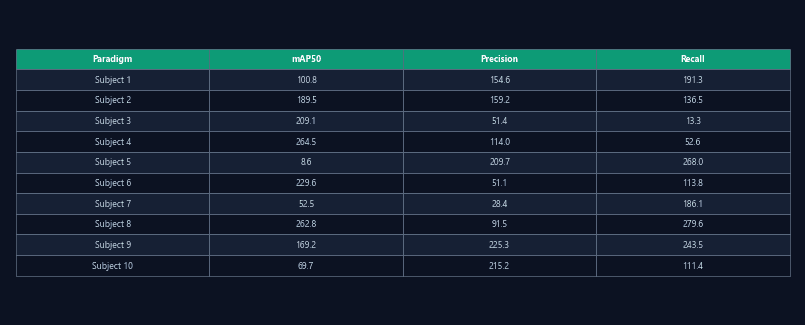
Per-paradigm accuracy tables
Precision, recall, and mAP50 for each detection model evaluated on each of the 24 paradigms. Reported with confidence intervals.
CSVPDF
Detection and pose accuracy validated across 24 behavioral paradigms
ConductVision publishes per-paradigm precision, recall, and mAP scores — not just overall accuracy numbers, but results specific to your experimental setup.

Most tracking software reports a single accuracy number for "rodent tracking" without specifying which paradigm, lighting, arena, or camera angle was tested. A system validated on open field may fail on water maze or social interaction.
ConductVision evaluates 20+ detection models per paradigm and publishes precision, recall, mAP50, and fitness metrics — the same validation data you would include in a methods section.
Precision, recall, and mAP50 for each detection model evaluated on each of the 24 paradigms. Reported with confidence intervals.
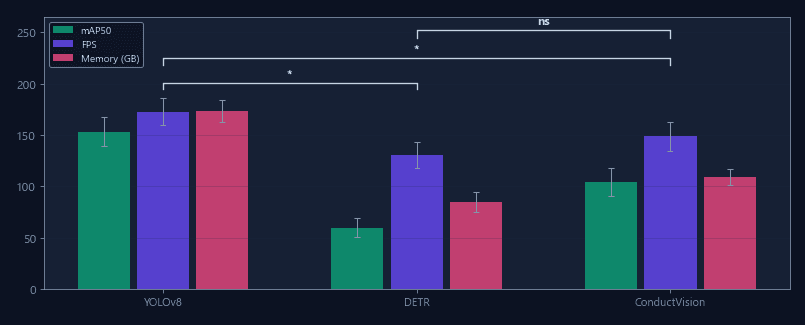
Composite fitness score combining precision, recall, and mAP across evaluation sets. Guides model selection for your paradigm.
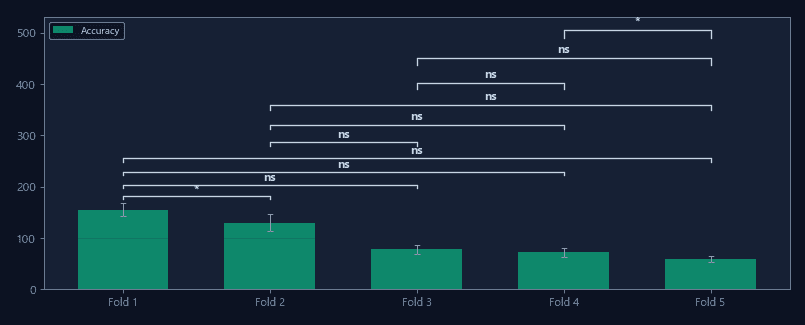
k-fold cross-validation performance to assess generalization. Separate train/test splits ensure benchmarks reflect real-world performance.
Include published mAP and recall scores directly in your methods section. Reviewers can evaluate tracking quality without additional validation experiments.
Compare detection performance across 20+ models evaluated on your specific test type. Select the model with the best accuracy-speed tradeoff for your setup.
Use published benchmark data to support ConductVision in equipment justification sections of R01, R21, and other NIH mechanisms.
Compare your experiment detection metrics against published benchmarks to verify tracking quality before proceeding to analysis.
| Feature | ConductVision | Typical systems |
|---|---|---|
| Published benchmarks | Per-paradigm, 24 tests | Single overall number |
| Models evaluated | 20+ per paradigm | 1 proprietary model |
| Metrics reported | Precision, recall, mAP50 | Accuracy percentage only |
| Cross-validation | k-fold results published | Not reported |
| Reviewer accessibility | Data tables available pre-purchase | Requires license to evaluate |

Side-by-side feature and performance comparison with EthoVision, ANY-maze, and other tracking platforms.

Train and validate custom behavior classifiers on lab-specific annotated data.

High-resolution 30 fps tracking that captures sub-second behavioral events conventional systems miss.
Browse per-paradigm accuracy data before downloading — no license required to evaluate.